
Aprenda o que é WebScraping, suas utilidades e como realizar com Python. Extraia dados da web de forma eficiente e legal.
Tempo de Leitura: 7 minutos
Neste artigo, vamos explorar de maneira clara e acessível um termo crucial na área de dados, o WebScraping. Sua utilidade pode surpreender, e as aplicações são numerosas, dependendo da sua criatividade.
Já imaginou as novas possibilidades que teria se pudesse obter automaticamente os dados disponíveis na Web? Se você, assim como eu, adora mergulhar nos dados em busca de uma visão orientada por dados sobre qualquer assunto, este conteúdo é para você!
Na área de dados (Data Science), sabemos que os dados são nossos principais ativos. Através deles, realizamos análises e auxiliamos na tomada de decisões. Portanto, é crucial termos dados para analisar. É exatamente neste ponto que vamos focar hoje: em uma forma muito útil e prática de obter novos dados.

O que é WebScrapping?
O termo WebScraping, também conhecido como "Raspagem de dados" em português, refere-se a técnicas utilizadas para extrair dados de aplicações web, comumente empregadas para automatizar a obtenção de informações de diversos sites.
Após compreender esse conceito, você pode estar se perguntando: "Como exatamente conseguimos obter os dados de um site com essa técnica?". Explicarei de forma simples como realizamos a extração de dados de um site por meio dessas técnicas de WebScraping.
Toda página web, por padrão, utiliza uma linguagem chamada HTML, responsável por estruturar e formatar o conteúdo da página, incluindo textos, imagens e links. O WebScraping opera navegando através desse HTML visível para obter as informações desejadas. Em outras palavras, manipulamos o HTML da aplicação para localizar e coletar as informações desejadas.
Para quê serve o WebScraping?
Como vimos anteriormente, o WebScraping nos permite extrair dados de aplicações web, isso por si só já demonstra uma utilidade inestimável, pois, essa técnica nos fornece uma nova maneira de obter dados que pode ser usada em inúmeros casos. Para exemplificar e deixar mais claro essa utilidade vamos descrever abaixo alguns dos casos onde o WebScraping pode ser utilizado.
Monitoramento de Preços:
Uma utilização muito popular é para realizar a comparação de preços em diferentes sites, no qual o WebScraping é utilizado para extrair preços de um mesmo produto em N sites diferentes e com isso podemos entender onde o produto está mais barato.
Avaliação de Opiniões:
Uma aplicação amplamente adotada é a comparação de preços em diferentes sites. Por meio do WebScraping, podemos extrair preços de um mesmo produto em diversos sites, permitindo identificar onde o produto está mais acessível.
Geração de Leads:
Pesquisar e coletar informações de contatos e dados relevantes para a prospecção de clientes é uma prática comum. O WebScraping torna esse processo mais eficiente ao automatizar a extração dessas informações de diferentes fontes online.
Extração de dados Financeiros:
Um dos usos mais populares do WebScraping é a extração de dados financeiros relacionados a ações, auxiliando na análise e tomada de decisão sobre em quais ativos investir.
Estes são apenas alguns exemplos de uso do WebScraping. É importante ressaltar que essa técnica é uma ferramenta versátil para extrair dados de aplicações web, podendo ser adaptada para uma variedade de necessidades, dependendo do contexto específico.
WebScraping: legal ou ilegal?
Sabendo que através do WebScraping podemos obter as informações das páginas web você deve estar se perguntando “Isso não séria ilegal ? Por poder obter as informações ‘sem pedir’ a página”.
Não ! A prática do WebScraping não é considerada ilegal. Pois, quando um site publica os dados, geralmente esses dados ficam disponíveis para o público e portanto podendo ser coletados livremente. Porém, nem todos os dados são legais de coletar, existem informações nas páginas que não são feitas para serem públicas, principalmente após a LGPD, resultando que a coleta de dados pessoais são restritas e necessitam da autorização prévia do titular destes dados.
Muitas páginas criam ações para barrar ou orientar quais informações podem ou não ser extraídas através de WebScraping, um exemplo disso é a confecção do arquivo robot.txt, esse arquivo consiste na orientação informando o que pode ou não ser acessado.
Em resumo é necessário entender que a prática de WebScraping não é ilegal, mas recomendamos sempre usar com cuidado e ética, respeitando e entendendo quais informações você poderá coletar sem problemas.
2 abordagens para realizar WebScraping com Python

Legenda: As abordagens diferem nas bibliotecas utilizadas e na escolha da mais apropriada para extrair os dados da página. | Imagem: Freepik
Ao decorrer deste artigo vou demonstrar um exemplo prático de como extrair informações de páginas web usando técnicas de WebScraping, porém, antes disso gostaria de explicar duas abordagens diferentes de como realizar isso.
A primeira diz respeito à extração de dados em sites estáticos cujo objetivo é obter o HTML da página e extrair os dados sem realizar nenhuma interação com a página. A outra abordagem é referente a sites dinâmicos usadas também para automações, pois, torna-se necessário realizar interações com a página para encontrar as informações desejadas e a partir daí extrair elas do HTML, quando comentamos sobre interações entende-se como qualquer ação necessária como por exemplo realizar o login ou até mesmo clicar em botões e etc.
Ambas as abordagens utilizam bibliotecas distintas e a principal diferença entre essas abordagens está no entendimento de qual delas conseguirá suprir a necessidade de extração dos dados na página selecionada. Em outras palavras, é preciso entender como a informação está estruturada na página para descobrir qual das duas abordagens utilizar.
Sites estáticos - BeautifulSoup4
Essa abordagem é relacionada aos sites estáticos onde não existe a necessidade de interações com o site, para facilitar o entendimento do que é um site estático faremos a seguinte analogia: “Um site estático é como uma página impressa: as informações estão lá, mas não mudam sozinhas; é como folhear um livro, onde cada página já tem tudo o que você precisa ver.”. Alguns exemplos de sites estáticos são sites informativos, institucionais, blogs pessoais, documentações entre outros que sigam essa premissa.
Nessa abordagem utilizamos a biblioteca BeautifulSoup4, após obter o HTML da página através de uma requisição HTTP, usamos essa biblioteca para navegar e extrair as informações de dentro da estrutura do HTML.
Em relação aos prós e contras desta abordagem, a grande limitação dela é o fato de não ser possível realizar interações com as páginas, portanto, páginas que necessitam login não funcionarão nesta abordagem. Em contrapartida ela é uma abordagem mais simples e rápida de aprender, sendo assim, quando for necessário extrair dados de sites estáticos essa abordagem tende a ser mais rápida e prática além de consumir menos recurso computacional.
Sites Dinâmicos - Selenium (documentação)
Quando necessitamos extrair informações de sites dinâmicos, ou seja, sites que necessitam interações e possam exibir diferentes conteúdos dependendo do usuário, torna-se necessário uma abordagem diferente, pois a abordagem anterior não funcionará.
Nessa abordagem utilizamos a biblioteca Selenium que existe também em outras linguagens de programação, cujo objetivo é automatizar a interação de um navegador web, ou seja, conseguimos navegar na web através de uma linguagem de programação como, por exemplo, o Python. Essa navegação consiste em realizar ações como, por exemplo, abrir links, clicar em botões, preencher formulários, navegar por páginas entre outros.
O fato do Selenium automatizar essa navegação nos permite realizar a extração de dados (WebScraping) interagindo com as aplicações, ou seja, podemos realizar login para acessar mais informações e até mesmo navegar pelo site para encontrar as informações que desejamos. Por este motivo o Selenium aumenta muito as possibilidades de realização do WebScraping, além também de poder ser utilizado para automatizações como preenchimento automático de formulários.
Como nem tudo são flores, o Selenium possui alguns pontos de atenção, como, por exemplo, não ser tão simples de aprender, dificuldade maior para configurá-lo principalmente em ambientes virtuais e o fato de maior consumo de recursos computacionais.
Em geral, essa abordagem possui uma maior utilidade, conseguindo através dela suprir as necessidades para realizar este processo de WebScraping, portanto aprender sobre ela lhe trará um leque muito maior de possibilidades.
Web Scraping com Python na prática

Legenda: Sempre que pretendemos obter informações de uma página, precisamos entender como a mesma está estruturada. | Imagem: Freepik
Agora, vamos colocar em prática o Web Scraping utilizando a primeira abordagem com a biblioteca BeautifulSoup4. Nosso objetivo é extrair dados das postagens realizadas no fórum da Casa do Desenvolvedor, que está disponível em Python. (Já aproveito e deixo o convite para todos conhecerem o fórum!)
Sempre que pretendemos obter informações de uma página, precisamos entender como a mesma está estruturada. Para isso, vamos utilizar o recurso de inspeção do navegador. Ao abrir o menu de Inspeção (Botão direito + Inspeccionar), podemos selecionar na visualização a parte que desejamos investigar.
Ao abrir o menu de Inspecionar (Botão direito + Inspecionar) usamos esse botão em verde na imagem para podermos selecionar na visualização a parte que queremos e ele nos mostrará no menu direito como as informações estão estruturadas no HTML.
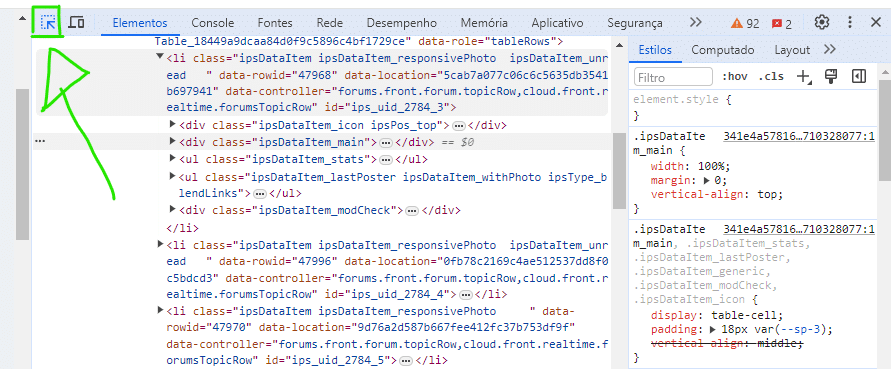
Na imagem abaixo, isso torna-se bem visível. Ao selecionar a parte que desejamos ver no HTML, ela é destacada em azul dentro do código. No nosso caso, sabemos que cada tópico corresponde ao elemento <li> cuja classe será ipsDataItem.
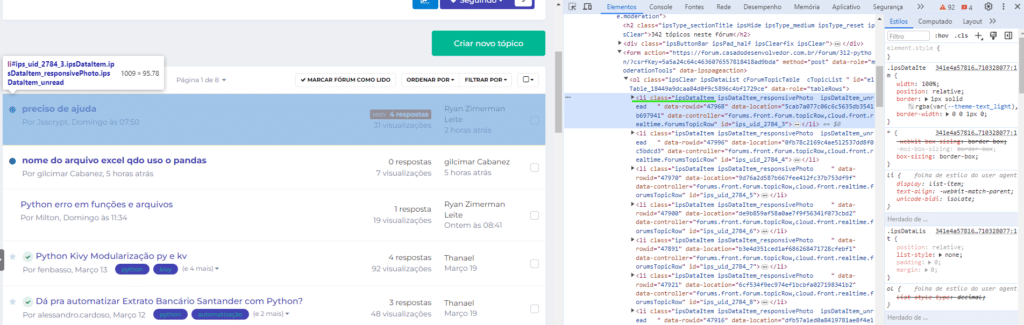
Agora, entendendo como essas informações estão estruturadas, vamos dar início ao nosso código para obter as informações desejadas. Lembre-se sempre de usar o recurso de inspeção na página para entender como as informações estão organizadas.
Segue abaixo como ficará o código devidamente explicado:
# Importação das Biblitoecas
#!pip install bs4
from bs4 import BeautifulSoup
import requests
import pandas as pd
# Link da página
url = "https://forum.casadodesenvolvedor.com.br/forum/312-python/"
# Realizar a requisição na página
req = requests.get(url)
# Usar o BeautifulSoup para ler o HTML
soup = BeautifulSoup(req.content)
# Existem diversas formas de usar o soup.find( ) recomendo verificar na internet qual achar mais fácil de utilizar
# Obter todos os tópicos mostrados
topicos = soup.find_all('li',{'class':'ipsDataItem'})
# Criar um DataFrame vázio para armazenar os dados
df = pd.DataFrame()
# Navegar por cada tópico
for topico in topicos:
# Obter as informações de cada topico (É necessário usar o Inspecionar para entender como elas estão estruturadas)
data = {
'titulo' : topico.find('h4', {'class':'ipsDataItem_title'}).getText().replace('\t','').replace('\n',''),
'atividades' : topico.find('span', {'class':'ipsDataItem_stats_number'}).getText(),
'visualizacoes' : topico.find_all('span', {'class':'ipsDataItem_stats_number'})[1].getText(),
}
# Juntar tudo ao dataframe inicial
df = pd.concat([df, pd.DataFrame([data])], ignore_index = True)
df.head(20)
O resultado deste código consistirá em um DataFrame contendo os dados relacionados às postagens do fórum, pronto para análise ou para ser inserido em um banco de dados. Veja o resultado abaixo.
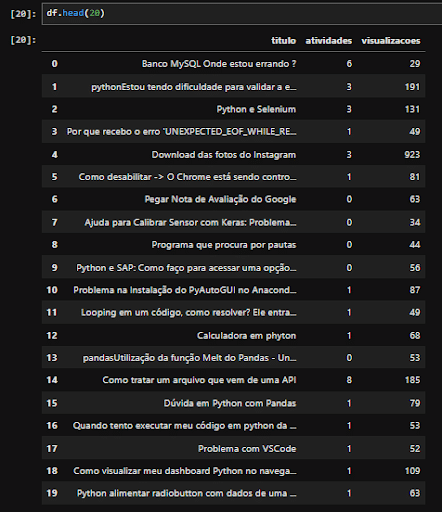
Em resumo, o Web Scraping é uma técnica muito útil para realizar extração de dados, através dele conseguimos de certa forma acesso a uma fonte “inesgotável de dados”, pois, atualmente existem inúmeras aplicações web.
No entanto, lembre-se que “Com grandes poderes vem grandes responsabilidades” (Desculpem a referência clichê haha mas encaixou tão bem no tema). Ou seja, é importante lembrarmos principalmente das questões éticas envolvendo essas extrações de dados e utilizarmos com sabedoria, entendendo que não são todos os dados que podemos extrair.
Finalizando, espero que eu tenha conseguido introduzir este tema tão importante da área de dados para vocês e que tenha aguçado sua curiosidade para querer saber mais sobre o tema e querer aplicá-lo em seus projetos pessoais ou profissionais.



