Descubra o impacto vital da Análise de Dados na estratégia empresarial. SQL, visualização e storytelling para decisões fundamentadas e sucesso.
Tempo de Leitura: 9 minutos
Olá , tudo bem? Hoje irei descrever um pouco sobre a Análise de dados que vem se tornando uma peça fundamental nas estratégias empresariais modernas, impulsionando a tomada de decisões pautadas em dados.
Neste artigo, exploraremos alguns casos específicos e técnicos da análise de dados utilizando SQL, destacando a relevância do tratamento e visualização de dados que são partes importantes desse processo.

A importância da Análise de Dados:
Como os dados são a base de informações valiosas, a análise de dados proporciona à gerência a tomar decisões estratégicas e táticas fundamentadas em um ambiente orientado a dados, impulsionando o sucesso e crescimento da empresa como um todo.
Além disso, a análise de dados permite a identificação de tendências emergentes, padrões e oportunidades de crescimento, fornecendo uma visão antecipada das mudanças no mercado e no comportamento do cliente, preparando melhor a equipe de Sucesso do Cliente, Marketing e Vendas dentre outros departamentos e assim proporcionando uma vantagem competitiva.
Outro ponto interessante, é o fato de possibilitar que a empresa identifique áreas de ineficiência operacional ou de risco e otimize processos internos e implemente medidas preventivas e mitigadoras para aumentar a eficiência e consequentemente reduzir seus custos.
Portanto, a análise de dados não é apenas uma ferramenta, mas um pilar fundamental para o futuro empresarial. Seja na tomada de decisões estratégicas, inovação ou melhoria em processos, a possibilidade de extrair valor de dados é um componente essencial para empresas de todos os portes e setores que buscam prosperar em um ambiente de negócios desafiador na era da informação.
Tratamento de dados utilizando SQL
Antes de começar a falar sobre o tratamento de dados é preciso entender o que é ETL.
ETL é um processo de pipeline de dados tradicional e a sigla significa: ‘E’ de Extração, aqui é a parte de obter os dados, seja de uma planilha, banco de dados, API ou outros sistemas, podendo ser dados brutos, ou filtrados. ‘T’ significa transformação, aqui entra a parte do tratamento de dados em si, limpeza de dados como correções de erro de digitação e/ou eliminação de dados duplicados, conversões necessárias para adaptar o dado ao padrão do novo repositório, como, por exemplo, conversão do formato de data ‘22/03/2022’ para o formato ‘2022-03-22’, agrupamento de dados, categorizações que irei explicar melhor ao decorrer do artigo.
A sigla ‘L’ significa load ou carga onde os dados são carregados ao seu destino, geralmente um banco analítico ou outro repositório para fins de análise. Lembrando também que existe o ELT, onde as etapas de transformação e carregamento de dados são invertidas. Entendendo isso, abaixo relatei alguns tratamentos de dados básicos utilizando SQL em casos específicos.
Mas afinal, o que é SQL (Structured Query Language)?
SQL é uma linguagem utilizada na comunicação com banco de dados, e não é uma linguagem de uso geral como o Python ou C, por exemplo. Essa linguagem é única e exclusivamente para uso no banco de dados relacional. Todo banco de dados relacional possui funções, sintaxe SQL e recursos distintos, portanto por mais que seja a mesma linguagem, muitos aspectos podem mudar de um banco para outro necessitando de adaptações caso haja uma migração de base.
Exemplos de limpeza de dados:
É muito comum encontrarmos casos de duplicação nos dados, então precisamos remover essa duplicação.
Como encontrar dados duplicados?
Através do código exemplo abaixo é possível descobrir se existem dados duplicados, se a consulta retornar 0 significa não haver duplicação.
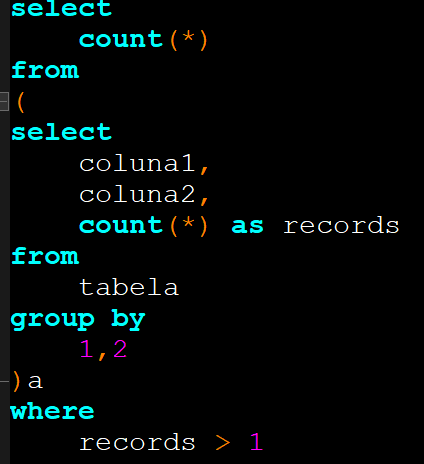
Outra alternativa, quando é preciso entender qual linha está duplicando, utilizar a query abaixo:
Nas duas situações acima, foi descoberto a duplicação, porém não como resolver essa situação. Abaixo existem alguns exemplos de como contornar uma situação de duplicação em casos em que não é possível corrigir na própria fonte de dados, então é preciso tratar essa questão posteriormente na análise de dados.
Existem casos em que os dados não são duplicados por problemas na qualidade dos dados, mas sim porque estamos relacionando uma tabela A com uma tabela B contendo muitos registros, por exemplo.
No caso abaixo existe um relacionamento exemplo da tabela de clientes que contém registro único de cada cliente, como informações de contato, CEP, porte, etc., e esta tabela está sendo relacionada com uma tabela de transações, podendo conter de uma ou mais transações por cliente.
O exemplo abaixo mostra que não faz diferença utilizar o distinct, devido à tabela de transações que pode conter mais de um registro por cliente, sendo isso normal em uma tabela de transações:

Resultado com duplicidade não causada por erros ou má qualidade dos dados da fonte. O nome do cliente se repete por conta do número de transações.

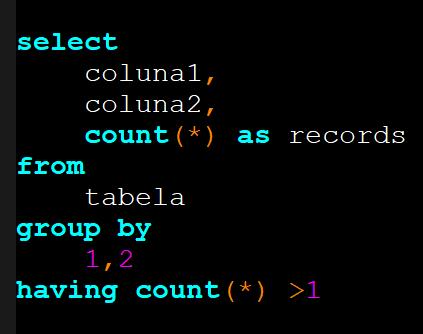
Para corrigirmos essa duplicação e analisar os dados de uma forma mais clara podemos utilizar o distinct com o group by, como no exemplo abaixo:

Resultado da query acima:
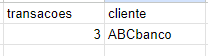
No resultado, a primeira coluna mostra a quantidade de transações já somada e a segunda coluna mostra a identificação do cliente, portanto a quantidade de transações por cliente de uma forma mais organizada. As funções de agrupamento permitem realizar operações em conjunto de dados agrupados como soma SUM(), contar número de linhas COUNT(), como no exemplo acima, média de valores AVG(), valor máximo de uma coluna MAX() e mínimo MIN(). Essas são as funções de agregação mais utilizadas na criação de análises.
O case é outro componente prático e bem utilizado até em casos de duplicação. A utilização do case é vantajosa para realizar agrupamento de categorias e padronização de valores.
Os valores que precisam de tratamento de padronização normalmente vem da fonte com formato de tags onde vários usuários podem escrever de vários formatos em um campo específico, como, por exemplo, podem digitar, ‘S’, ‘SIM’ ou ‘sim’, de várias formas sem um padrão definido. A confiabilidade dos dados diminui com a utilização de campos abertos em decorrência de erros que poderiam ser resolvidos de uma forma simples na fonte sem a necessidade de um tratamento de dados posterior, adotando a medida de utilização de campos de valores fixos, por exemplo.
Abaixo um exemplo de tratamento de dados utilizando o case, com a intenção de padronizar o valor da coluna campo_resposta como ‘Sim’.
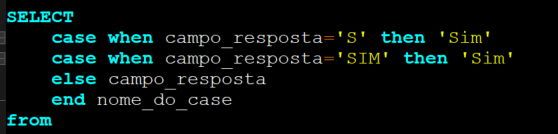
Em outro cenário, podemos utilizar a instrução case como lógica para adicionar uma categorização. Como utilizar o case no tratamento de registros de NPS (Net Promoter Score) o indicador que monitora o sentimento do cliente.
Os participantes da pesquisa classificam em uma escala de 0 a 10 seu sentimento positivo em relação ao produto, empresa, atendimento, etc. Então a partir disso, uma empresa A que utiliza essa pesquisa pode considerar que seus clientes que avaliaram o NPS de seu produto na faixa de 0 a 6, estará classificado como ‘depreciativo’, na faixa de 7 a 8 como ‘passivo’ e a partir de 8 como ‘incentivadores’. Com isso, temos um novo campo chamado tipo_resposta que avalia essa pontuação utilizando a instrução case como mostra na imagem abaixo.

Essa técnica usando o case pode ser muito útil desde que as variações sejam curtas, quando temos a faixa definida, no caso do exemplo acima temos 3 possibilidades de categoria e um valor de 0 a 10 que o cliente pode atribuir. Em casos em que a faixa de valores registrados não é definida, onde o usuário pode inserir diversos tipos de valores em um campo, não é recomendado a utilização do case, pois a variação de valores seria muito abrangente e instável.
Outro ponto relevante na análise de dados é o tratamento de dados nulos e string vazias.
Dependendo da análise, podemos considerar ou desconsiderar campos nulos, ou string vazias, sempre será algo muito específico da análise em questão. No exemplo de dados nulos estes indicam a ausência de valor, o valor do campo aparecerá como ‘NULL’. Já a string vazia, além de ser um tipo diferente por se tratar de uma sequência de caracteres, não aparece valor algum no campo. Ao utilizar a função de agrupamento de Count() em um campo com somente valores nulos, o resultado será zero, ou seja, não contabilizará valores nulos. Não acontece o mesmo com string vazias.
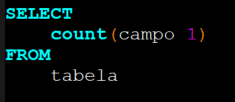
Exemplo utilizando count() em um campo nulo:
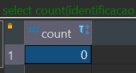
Resultado da query acima:
Em se tratando de strings vazias, estas são contabilizadas como se fosse um campo com valor normal. Resultado se o campo fosse uma string vazia: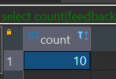
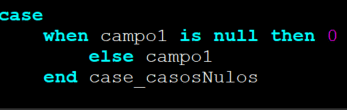
Como os valores nulos não são contabilizados, tendo a necessidade de contabilizá-los para uma análise específica, podemos utilizar o Case ou o Coalesce.
Exemplo de caso utilizando o case para contabilizar nulos.
Podemos também utilizar o coalesce como forma de transformar valores nulos em zero para que este passe a ser um valor contabilizado.
![]()
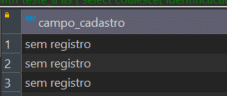
Existem cenários, onde o preenchimento de dados na fonte é opcional como aquele formulário que preenchemos que aparece o número de telefone obrigatório e outro campo opcional, quando esse dado não é preenchido ele pode vir nulo para o banco de dados, e é aí que entra o coalesce novamente, podemos utilizá-lo para deixar o campo não preenchido como uma resposta padrão. No exemplo abaixo, preenchemos o nome do campo e o texto que queremos que apareça em caso do campo não ter sido preenchido. 
Resultado da query mostra a resposta padrão em campos que vieram nulos:
Outro cenário interessante para utilizar o coalesce é no seguinte cenário:
Uma empresa contém 3 campos para serem preenchidos em um formulário para clientes com campos contendo e-mails de financeiro, administrativo e técnico, podendo estar preenchidos ou não, nesse cenário poderíamos usar um case avaliando se cada campo está preenchido e retornar uma resposta padrão ou simplesmente utilizar o coalesce avaliando cada um dos 3 campos, se o campo 1 tiver preenchido retorna o campo 1, caso o 1 não esteja preenchido e o 2 esteja preenchido, então retorna 2 e vice-versa, mas caso não houver nada preenchido apenas retorne ‘sem e-mail’ simplificando a lógica sem a necessidade de usar a instrução case.
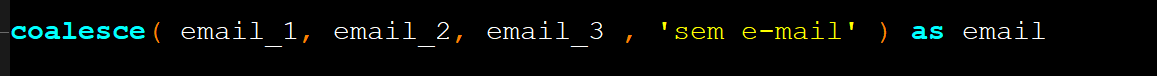
Assim, vimos um pouco sobre a utilização do distinct ,função de agrupamento count , case e coalesce em casos específicos para tratamentos iniciais em uma transformação de dados.
Constatamos que a linguagem SQL e o tratamento de dados é inevitável e útil no dia a dia de um Analista de Dados, proporcionando insights valiosos na utilização do banco de dados relacional permitindo consultas e manipulações que tornam os dados mais acessíveis e limpos para utilização posterior em relatórios e dashboards, permitindo uma análise com maior confiabilidade e clareza. Importante lembrar que a linguagem Python e R também são muito requisitadas na análise de dados e poderiam ser assunto para uma próxima pauta.
Visualização dos dados
Entre um dos inúmeros produtos resultantes do trabalho de um Analista de Dados é a visualização de dados, que é a representação visual desses dados , transformando-os em números, gráficos,tabelas entre outros elementos visuais que possibilitam um rápido entendimento mesmo por pessoas leigas. Então, assim que é realizada a transformação dos dados e esses se encontram tratados em um repositório, podemos usá-los para visualização.
A visualização eficiente de dados facilita a comunicação entre equipes, permitindo que profissionais de diferentes setores compreendam e aproveitem as informações disponíveis.
Todo analista precisa usar formatos adequados para que os dados se tornem acessíveis para seu público-alvo em questão, cumprindo com seu objetivo de transmitir a mensagem que os dados carregam. Mas em termos de ferramentas do mercado , quais são as mais conhecidas? Podemos destacar o Tableau, Power BI ,Qlik , Google Data Studio , Looker , Metabase entre inúmeras outras ferramentas que existem no mercado.
Dentro dos conceitos de visualização, está o Storytelling , "história de dados” que é a capacidade de transmitir as respostas dos dados aos seus leitores em um curto espaço de tempo e com menos esforço.
Um dos exemplos da eficiência do storytelling é que este responde o 'porque', em contrapartida das planilhas e painéis que somente mostram 'o que' aconteceu.
Mas afinal do que é feito o storytelling ?
O Storytelling possui 3 elementos importantes: dados, narrativa e recursos visuais.
Basicamente como um ciclo:
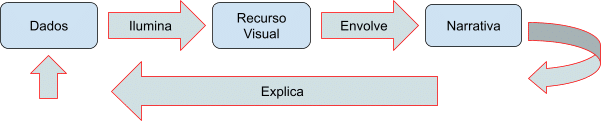
Os dados iluminam os Recursos Visuais que envolvem a Narrativa explicando os Dados!
Isso resume a frase de Stephen Few, “Os números tem uma história importante para contar. Eles confiam em você para dar a eles uma voz clara e convicente”. Desse modo, a melhor forma de comunicar seus insights sobre os dados é através de uma história de dados.
E para complementar o conceito de Storytelling , abaixo deixei alguns exemplos de gráficos combinando com cada cenário citado.
Exemplo de gráfico de linha:
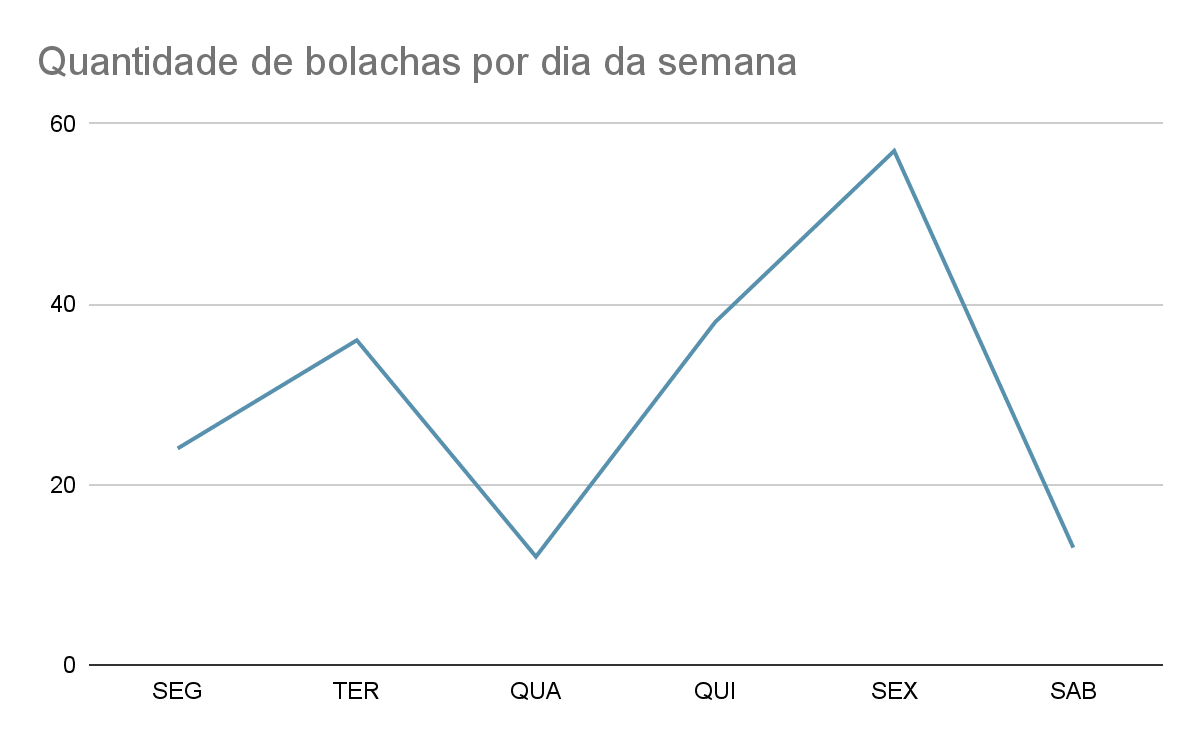
Adequados para mostrar análise de tendências facilitando a identificação de tendências entre duas variáveis como por exemplo comparações de quantidades ao longo de um período.
No exemplo acima é mostrado o número de bolachas vendidos por dia da semana para possibilitar um melhor entendimento de qual é o dia que é mais provável de ter aumento ou queda nas vendas e possibilitar um melhor planejamento para compra de materiais/produção das bolachas, por exemplo, o dia da compra do material poderia ser na quarta, visto que a partir de quinta começa a aumentar as vendas até o fim de semana.
Exemplo de Gráfico de barras empilhado (Stacked):
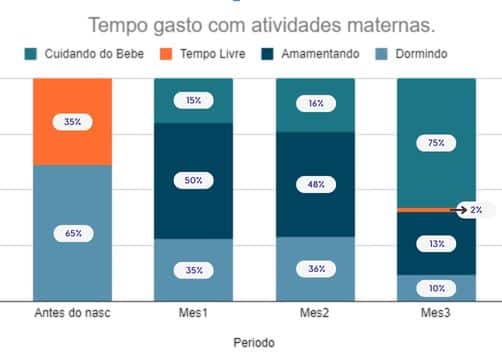
O gráfico acima mostra o exemplo de um cronograma com tempo gasto por uma mãe antes e depois da chegada de um recém-nascido. Esse gráfico pode ser usado como Indicador de mudanças ao longo do tempo como utilizado no exemplo acima, mostrando as porcentagens de tempo gastos em cada atividade materna.
Da mesma forma, diversos gráficos podem ser criados utilizando barras empilhadas como distribuição de receita e despesas, acompanhamento de metas por categoria, representação de totais cumulativos quando é necessário destacar a contribuição total de cada categoria para o conjunto de dados.
Exemplo de gráfico de pizza ou setor:
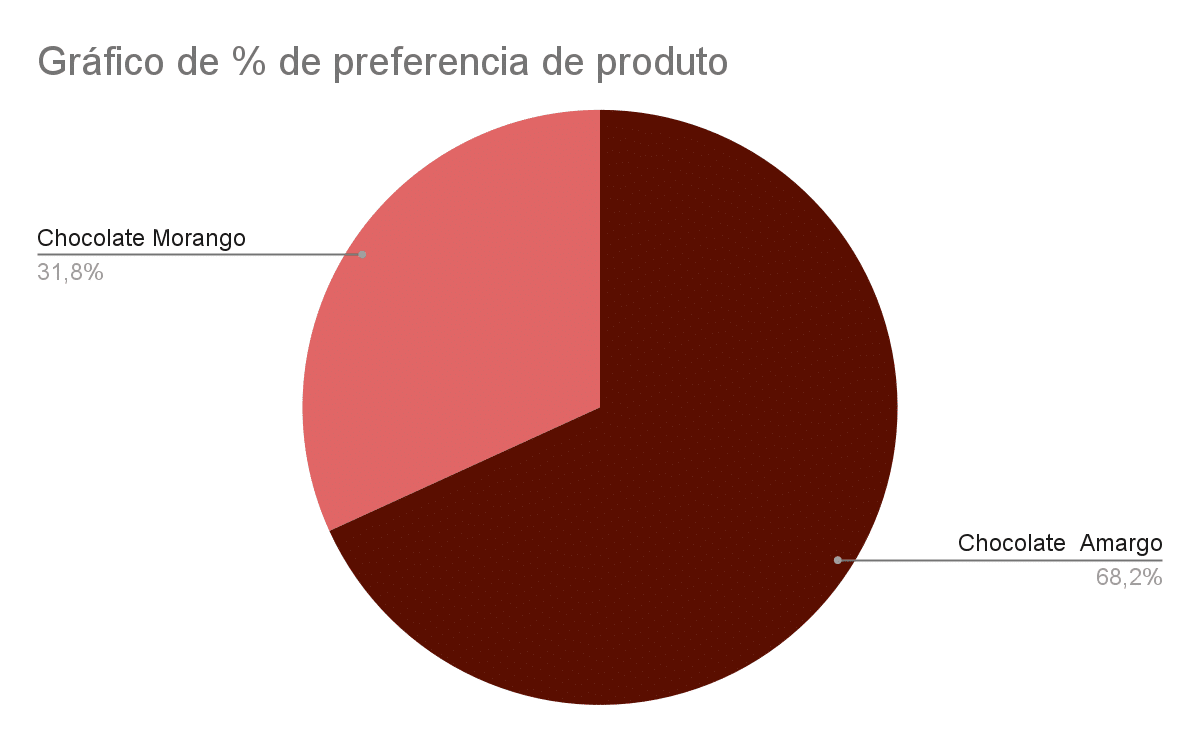
O gráfico de pizza é visualmente mais intuitivo e de fácil entendimento quando representado por valores percentuais e poucas categorias, permitindo um rápido entendimento sobre as proporções relativas de cada categoria em relação ao todo. Não sendo recomendado sua utilização quando existem muitas categorias, pois, pode tornar a visualização poluída dificultando a interpretação dos valores.
No exemplo simples acima, uma empresa possui dois produtos mais populares e precisa entender qual deles é o mais preferido/vendido em um determinado período do ano para investir neste uma estratégia de marketing específica.
Neste capítulo, abordei um pouco sobre alguns modelos de gráficos com exemplos específicos e técnicos de visualizações, levando em consideração a importância do conceito de Storytelling de dados, que através de narrativas objetivas podem resultar em insights valiosos.
Conclusão
Para concluir, vimos que a integração harmoniosa dos processos de análise de dados como tratamento e visualização de dados , resultam em uma abordagem eficiente para explorar, compreender e comunicar informações importantes a partir de dados concretos.
O tratamento traz a clareza e veracidade no conjunto de dados analisados , enquanto que a visualização trás os elementos visuais assertivos e objetividade na comunicação da mensagem. Criando indicadores robustos ,impulsionando assim a tomada de decisões estratégicas informadas nas mais diversas áreas, desde negócios até pesquisas científicas.
Gostou deste conteúdo?
Te convido a participar da nossa comunidade e trocar conhecimentos nas mais diversas áreas do ecossistema de tecnologia, basta clicar no botão abaixo:
Referências
- SQL para Análise de Dados por Cathy Tanimura.
- A cor dos dados por Kate Strachny.
- Storytelling com dados por Cole Nussbaumer Knaflic.



